[운영체제] 메모리 관리
메모리 관리

주소 바인딩
- symbolic address -> Logical Address -> (하드웨어가 주소 변환(주소바인딩)) -> physical address

Logical address
- 논리적인 주소
- 프로세스마다 독립적으로 가지는 주소공간
- CPU가 보는 주소가 logical address 임
physical address
- 물리적인 주소
- 메모리가 실제 올라가는 위치
주소 바인딩 종류
Compile time binding
- 컴파일과정에서 물리적인 주소가 결정됨
- ex. 특수한 목적에서 진행되는 컴퓨터 (제대로 된 데드라인을 지켜야 하는),
- ex. 하나의 프로세스만을 사용할 때 이 주소 바인딩이 편하다
- 컴파일러는 절대 코드(absolute code) 생성
Load time binding
- 실행이 될때 결정되는 물리적인 주소
- 메모리가 로딩 될 때 물리적인 주소가 매겨짐. (주소는 바뀌지 않음)
- 컴파일러가 재배치 가능코드(relocatable code)를 생성한 경우 가능(위치가 바뀔수있는 코드 라는 뜻)
Run time binding (Execution time binding)
- 실행이 될때 결정되는 물리적인 주소
- 프로그램이 실행되는 도중에 프로세스의 메모리 주소가 바뀔수있음
- CPU는 메모리에 접근할 때마다 주소를 점검해야함
MMU (Memory-Management Unit)
- = 주소변환 하드웨어
- CPU가 특정 프로세스의 논리적 주소를 참조하고 싶을 때,
- 그 주소값 + 레지스터값 => 물리적 주소 값을 얻어냄
- 2개의 기준 레지스터를 가짐(relocation register, limit register)

relocation register (=base register)
- 물리적인 시작위치
limit register
- 논리적인 주소의 범위 (메모리의 크기)
- 프로그램의 질이 안좋거나, CPU요청사항과 맞지 않은 경우를 막기 위해서 범위를 정함
- 맞지않은 경우 trap 발생 (CPU 제어권이 운영체제에게 넘어감)
간단한 주소변환 방식(Dynamic Relocation)
- CPU가 346번지 논리적 주소를 요청
- -> relocation register 값을 더해서 주소 변환해서 CPU에게 전달 (14346번지가 됨)
- -> limit register 으로 3000 범위 내의 메모리 크기인지 확인
- -> 메모리 접근
사용자 프로그램
- logical address 만을 다룬다
- physical address 를 알수도 없고 알필요가 없음
몇가지 용어
Dynamic Loading
- 메모리를 미리 다 올려놓지 않고, 그때 그때 올림 (메모리 낭비를 막음)
- 운영체제의 특별한 지원 없이 프로그램 자체에서 구현 가능 (운영체제는 라이브러리를 통해 지원 가능)
- loading = 메모리에 올린다는 뜻
Overlays
- 메모리의 프로세스의 부분 중 실제 필요한 정보만을 올림
- Dynamic Loading과 비슷하지만, 조금 옛날 용어임
- 작은 공간의 메모리를 사용하던 초창기 시스템에서 수작업으로 프로그래머가 구현하는 것
- (프로그래밍이 매우 복잡해짐)
메모리 관리 전략
메모리 관리 배경
- 프로세스가 cpu 할당되기 전, OS에서 메모리를 관리하고 거침
- swapping(중기스케줄러 관련), fragmentation(단편화), paging, segmentation
Swapping
- 메모리가 한계에 다다랐을 때,
- 프로세스를 일시적으로 메모리에서 backing store 로 쫓아냄

Backing store(=swap area)
- = 디스크
- 쫓겨나는 영역
Swap in / Swap out
- 일반적으로 중기스케줄러에 의해 swap out 당한 프로세스를 선정 (suspend 상태인 프로세스)
- CPU의 우선순위가 낮은 프로세스를 쫓아냄
- Compire time binding 혹은 load time binding 에서는 메인 메모리 위치로 swap in 해야함
- 위 주소 바인딩은 주소가 정해져있어서 비효율적임
- Run time binding 에서는 추후 빈 메모리 영역 아무곳에나 올릴 수있음
Dynamic Linking
- Linking 을 실행시간까지 미루는 기법
Static linking (<- static library)
- 내가 만든 코드 + 라이브러리 포함 => 실행파일 만듬
- 미리 컴파일 되어 컴파일 시간 단축
- 동일한 라이브러리를 각각의 프로세스가 쓰게되어 메모리 낭비가 됨
Dynamic linking (<- shared library)
- 라이브러리가 프로그램 실행 시 연결됨
- 메모리 낭비는 적지만, 먼 라이브러리 주소로 건너가야 해서 오버헤드 발생
연속 할당
- = 각각의 프로세스가 메모리의 연속적인 공간에 적재되도록 하는 것 (통째로 올라감)
- 고정분할 방식
- 물리적 메모리가 들어갈 공간을 여러개의 파티션으로 미리 나누어놓는 것
- 내부조각이 생겨서 크기가 안맞아서 낭비될수있음
- 가변분할 방식
- 메모리를 미리 나누어놓지 않고, 메모리를 넣은 다음 나머지는 외부조각으로 보기
- 외부조각 낭비
- Contiguous Allocation
- Dynamic Storage-Allocation Problem
- 가변분할 방식에서 size n인 요청을 만족하는 가장 적절한 hole을 찾는 문제
- first-fit : 크기가 n 이상인 것 중 제일 첫번째로 발견되는 hole 에 할당
- Best-fit : 크기가 n 이상인 가장 작은 hole을 찾아서 할당
- 불필요하게 큰 공간을 안써도 되서 효율적임
- 단점 : Hole을 다 뒤져봐야함
- Worst-fit : 가장 큰 hole에 할당
- 단점 : 더 큰 프로세스가 실행될때 넣을수없게됨.
first-fit 과 Best-fit 보다 속도, 공간이용률이 안좋음
- 단점 : 더 큰 프로세스가 실행될때 넣을수없게됨.
- Dynamic Storage-Allocation Problem
사용자 프로세스 영역의 할당 방법

물리적 메모리 할당
- 메모리는 일반적으로 두 영역으로 나누어 사용
- OS 상주 영역, 사용자 프로세스 영역
Hole
- 비어있는 메모리 공간 (가용 메모리 공간)
- 프로그램이 여러차례 실행/종료하다보면 이런 공간이 찔끔찔끔 흩어져있음
- 따라서, 운영체제는 할당/가용 공간을 유지해야 함

compaction
- external fragmentation (메모리 공간이 작은 조각(외부/내부 조각)으로 나누어져 사용이 불가능한 상태.)
- 위 문제를 해결하기 위해 비어있는 공간을 연속적인 공간으로 만들고 움직이는 작업
- 빈공간이 있음에도 활용이 잘 안될 때,
- 사용중인 메모리 영역을 한군데로 모아 hole 들을 다른 한곳으로 몰아 큰 block을 만드는 것
- 단점 : 매우 비용이 많이 듬
불연속 할당
Paging
- 프로세스의 주소공간(가상메모리)을 동일한 크기의 page 단위로 나눔
- 물리적 메모리의 각각 다른 위치에 페이지들을 저장함
- 모든 프로세스가 각각의 페이지 테이블을 가짐
- 페이징 기법
- 물리적 메모리를 동일한 크기의 페이지 단위로 프레임을 나눔
- 외부 단편화가 발생하지 않음
- 외부 단편화 : 메모리 크기의 단위 < 들어갈 프로그램의 크기 인 경우에 프로그램이 들어가지 못함
- 내부 단편화 : 메모리 크기의 단위 > 들어갈 프로그램의 크기 인 경우에 사용하지 않은 메모리 조각이 발생
- 장점
- 프로세스 전체를 통째로 넣을 필요 없이 특정 크기의 페이지로 잘라서 넣을 수 있음
- 동적 메모리 할당 문제(메모리 주소 공간 결정 문제) 가 발생하지 않는 장점
- 단점
- 메모리상 가용 공간의 크기가 작게 나누어져 있어,
- 다른 페이지가 남은 페이지를 또 채워주고 하면 되니까 외부조각 문제가 발생 X.
- 그러나 페이징으로 쪼갠 후 남는 자투리 공간 때문에 맨 마지막 페이지는 내부조각이 발생할 수 있음(내부 단편화)
- 외부조각 : 프로세스가 할당되지 않은 공간
- 내부조각 : 프로세스가 할당되고도 남은 공간
Page table
- 페이징 기법에서는 모든 프로세스가 각각의 주소 변화를 위한 Page table을 가짐
- 프로세스가 가질 수 있는 페이지의 개수만큼 주소변환 엔트리를 가지고 있게 됨

Page-table base register : page table 을 가리킴
Page-table length register : 테이블 크기를 보관
- 두개의 레지스터를 따라서 메모리 접근할때마다 2번의 메모리 주소 필요
- 오버헤드가 발생
TLB
- 주소변환을 빨리하기 위한 고속의 하드웨어 캐쉬
- (가격이 비싸고 용량이 적어서) 모든 페이지 테이블 정보를 확인할 수 없음
- associative register : 병렬탐색이 가능한 연관 레지스터 사용
Hit ratio : TLB를 통해서 주소변환이 이루어지는 비율
TLB miss : 주소변환 X
TLB hit : 주소변환 O

Two-level page table
- 2단계 이상의 다단계 페이지 테이블
- 페이지가 다시 페이지화 되는 것
- 현대의 컴퓨터는 매우 큰 주소 공간을 사용
- 하지만 대부분의 프로그램은 지극히 일부분만 사용하므로
- 메인 메모리에 연속적으로 할당되는 page table 들이 심하게 낭비됨
- 따라서, 페이지 테이블을 여러개의 조각으로 나누어야 함

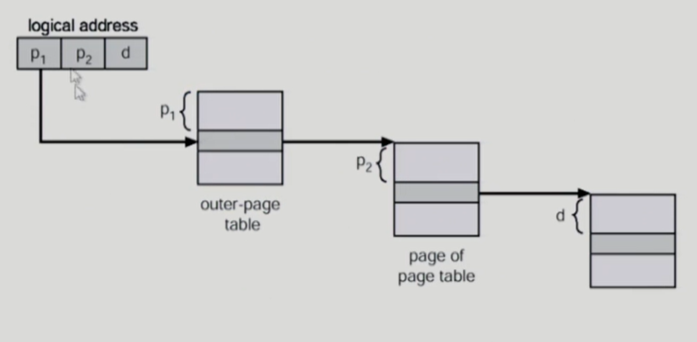
- 바깥 페이지 테이블은 전체 논리적인 메모리의 크기만큼 만들어짐
- 사용되지 않는 주소는 안쪽 페이지 테이블이 만들어지지 않음

메모리 보호 (Memory Protection)
- 페이지 테이블의 각 entry마다 아래의 bit을 둠
Protection bit
- page의 연산에 대한 접근 권한 (read/write/read-only => Page table Entries)
- Page table Entries 중 어떤 게 가능한지 알려줌
Valid-invalid bit
- 특정 페이지의 메모리 존재여부를 구분할 수 있음
- Page table Entries 의 사용 가능여부를 알림
- 이 비트는 각 프로세스를 구성하는 모든 페이지에 대해서 존재해야함
- 초기, 모든 page entry가 invaild 로 초기화되어 있음
- 특정 페이지가 참조되어 메모리에 올라가면 invaild -> vaild
- 메모리에서 swap area로 쫓겨나면 vaild -> invaild (= 이 주소를 사용하지 않겠다)
shared Pages Example

shared code
- 프로세스들이 같은 목적으로 공유할 수 있는 코드
- read-only로 하여 프로세스간의 하나의 물리적 코드만 올림
- shared code는 모든 프로세스의 동일한 논리적 주소에 위치해야함
segmentation 기법
- paging 처럼 일정 크기의 페이지 단위(물리적)로 자르는 것이 아닌, 논리적 단위인 segment로 자름
- 프로그램은 의미단위인 함수 하나하나 등을 여러개의 segment로 정의
- 논리적 단위로 나누었기 때문에, 각각 segment 크기가 균일하지 않음
- 세그먼트 길이가 균일하지 않아, segment 시작위치/정보/길이를 함께 보관
- 일반적으로는 code, data,stack 부분이 하나씩의 세그먼트로 정의됨
- 사용자/프로그래머 관점의 메모리 관리 기법

주소 변환 방법 (논리적 -> 물리적)
- STBR과 STLR을 사용함
- segment-table base register (STBR) : 프로세스의 segment table의 물리적 메모리 위치
- segment-table length register (STLR) : 프로세스의 segment 총 개수
- segment table
- 각 segment에 저장된 물리적 메모리의 주소를 표현하기 위한 단위들
- base : 물리주소의 시작위치
- limit : segment의 길이
- 각 segment에 저장된 물리적 메모리의 주소를 표현하기 위한 단위들
- 용어
- 논리적 주소 -> 세그먼트 번호+변위비트
- segment 간격(d) = 0~segment limit 사이의 값
- segment 번호(s) = segment table의 인덱스값
- 순서
- 세그먼트 번호(s)가 STLR 미만의 값인지 확인
- 논리적 주소의 오프셋 값이 세그먼트 간격값을 넘으면 운영체제에서 trap 발생시킴
- 오프셋 값을 상위/하위 비트로 나눔
- 상위 = segment table 내의 시작위치, 하위 = 페이지 변위비트
Segment Architecher

- protection
- 각 세그먼트 별로 protection bit이 있음
- read/write/execution 권한 bit
- sharing
- segment는 의미 단위이기 때문에 공유, 보안에 있어 paging보다 훨씬 효과적
- (paging은 크기단위로 유리)
- allocation
- first/best fit
- segment의 길이가 동일하지 않으므로 가변분할 방식에서의 동일한 문제점이 발생
Paged Segmentation

segmentation의 단점
- 외부 단편화 발생 : 가변적인 크기 때문에 동적인 메모리 할당이 필요하다 (메모리 낭비)
- 외부 단편화 문제 해결에 효과적인 페이징 기법을 사용해야 함
segmentation과의 차이점
- 외부의 segment table + 내부의 page table 사용
- 의미있는 단위로 자름(segmentation) -> 잘라진 segment를 다시 페이지 단위로 자른다(페이징 기법)
- 메모리 낭비가 줄어듬
- segment-table entry가 segment의 base address를 가지고 있는 것이 아니라
- segment를 구성하는 page table의 base address를 가지고 있음
- (페이지단위로 물리적 메모리에 올라감)
자세한 과정
- 논리적 주소인 segment 번호로 segment table의 base, limit 등 확인
- 문제 없을시 (문제 있으면 trap 발생), 오프셋 값을 segment 시작위치(상위) + 페이지 변위비트(하위)로 사용
Demend paging (요구 페이징)
- 요청이 있을시, 그 페이지를 메모리에 올리는 것
- 한정된 메모리 공간을 더욱 잘 활용 가능
- I/O, 물리적 메모리 사용량 감소
- 메모리에서 직접 서비스하는 비율이 높아짐 -> 응답시간 빨라짐

Page Fault
- Demanding paging 하는데 요청한 페이지가 메모리에 없을 때 (invalid)
- invaild page에 접근시 mmu가 trap 발생시킴
- invalid : 요청한 페이지가 메모리에 올라와있지 않은 상태
- CPU가 OS에게 넘어감 (커널 모드) -> OS가 fault 된 페이지를 메모리에 올림
- 발생하지 않을수록 메모리 관리가 잘 됨
- 발생 시, OS/HW의 작동, swap out, swap in 등의 오버헤드 발생
- 처리루틴
- 메모리 주소가 잘못된 접근인지 확인 (잘못될경우 abort 됨)
- 비어있는 메모리가 없다면 하나의 페이지를 쫓아내고 해당 페이지를 replace 함
- 디스크에서 페이지를 메모리로 읽어옴
페이지 교체 알고리즘
Optimal Algorithm
- 프로세스가 미래에 사용할 페이지를 미리 알아야 함 (따라서 구현은 불가능한 알고리즘)
- 앞으로 가장 오랫동안 사용하지 않을 페이지를 교체하는 알고리즘
- 페이지 교체 알고리즘들 중 가장 페이지 교체 수가 적음
FIFO Algorithm
- 메모리에 올라온지 가장 오래된 페이지를 교체함
- FIFO Anomaly 발생
- 메모리 프레임을 늘려줬는데 성능이 나빠짐
LRU Algorithm
- 가장 오래 사용되지 않은 페이지를 교체하는 알고리즘
- 최적 알고리즘 방식과 비슷한 효과를 냄
- 성능이 좋아 주로 이용하는 알고리즘
LFU Algorithm
- 참조 횟수가 가장 적은 페이지를 교체하는 알고리즘
- 교체 대상이 여러개면 가장 오랫동안 사용하지 않은 페이지를 교체함
다양한 캐싱 환경
캐싱 기법
- 한정된 빠른 공간(캐시)에 요청된 데이터를 저장해 두었다가,
- 또 같은 요청이 들어오면 빠른 캐시로부터 직접 서비스함
캐시 운영의 시간 제약
- 교체 알고리즘에서 삭제할 항목을 결정하는 일에 지나치게 많은 시간이 걸리는 경우 실제 시스템에 사용 불가
- 페이지가 이미 메모리에 존재하는 경우 참조시각 등의 정보를 운영체제가 알 수 없음 (중간에 OS의 개입이 없기 때문)
페이징 시스템에서 LRU, LFU 가능?
- CPU에서 프로세스A가 실행중
- 페이지 테이블을 통해 논리주소 -> 물리메모리주소 변환 (주소변환은 하드웨어만 관여함. OS의 개입 X) -> CPU로 읽어오기
- 이미 올라간 메모리에 대해서는 운영체제는 알수없기 때문에 CLock 알고리즘 필요 (최근에 쓴 페이지 등을 알수없음)
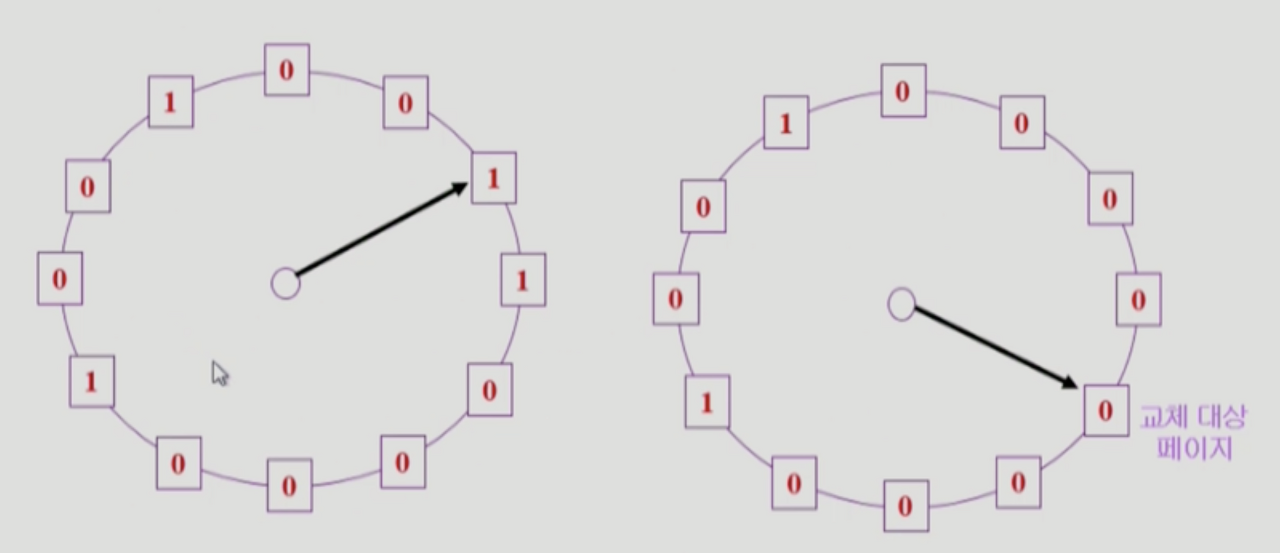
Clock Algorithm
- LRU 근사 알고리즘
- 시계모양처럼 페이지를 돌다가, 새로운 페이지를 디스크에 올리기 위해
- 최근에 사용 안된 페이지들을 쫓아내는 것
- 메모리 안의 페이지들이 존재.
- Clock algorithm 의 개선
- reference bit : 0 (최근에 사용 안된 페이지), 1 (최근에 사용된 페이지)
- 하드웨어 : 페이지가 사용이 될때 bit을 1으로 바꿈
- 운영체제 : 최근에 사용하지 않은 페이지를 쫓아낼때 bit을 0으로 바꿈
- modified bit : 최근에 변경된 페이지. 써준 뒤 쫓아내야 하기 때문에 1이면 쫓아내지 않는다
Page frame의 Allocation (할당)
- 할당의 필요성 : 프로세스가 원활하게 돌아가려면 페이지 프레임을 어느정도는 가지고 있어야 함
- 할당 문제 : 각 프로세스에 얼마만큼의 page frame을 할당할 것인가?
- 할당 방식
- Equal allocation : 모든 프로세스에 똑같은 갯수 할당
- Proportional allocation : 프로세스의 크기에 비례하여 할당
- Priority allocation : 프로세스의 우선순위에 따라 할당
Global replacement
- replace 시 다른 프로세스에 할당된 frame을 빼앗아 올 수 있음
- 프로세스 별 할당량을 조절하는 또 다른 방법
Local replacement
- 자신에게 할당된 frame 내에서만 replacement (바꿀수있음)
Thrashing Diagram

- cpu를 가동하다가, 점점 프로세스가 늘어나서 쓸 메모리가 적어지면(= 페이지 부재) thrashing 발생
Working-Set Model
Locality of reference
- 프로세스는 특정 시간동안 일정 장소만을 집중적으로 참조함
Working-set Model
- Locality에 기반하여 프로세스가 일정시간동안 원활하게 수행되기 위해
- 한꺼번에 메모리에 올라와있어야 하는 페이지의 집합 (= locality set)
- Working Set 모델에서는 프로세스의 working set 전체가 메모리에 올라와 있어야만 수행됨
- 그렇지 않을경우 모든 page frame을 반납 후 swap out
- thrashing 방지